Blog Post #6
Last blog post ended a bit abruptly so let me recap and add onto some things discussed on the last blog post.
The two_models branch utilizes two models: an off-the-shelf Coreference Resolution model and the Pointer-Generator model. The Coreference Resolution model is used during pre-processing and post-processing of the data. Before the training data is fed into the Pointer-Generator model to train the automatic summarization model, the data goes through the Coreference Resolution model where the model replaces all the pronouns with the noun that the pronouns are referring to (e.g. The text "Wayne saw himself." becomes "Wayne saw Wayne.") and saves the noun and the pronouns (e.g. {Wayne: [he, his, him, student]}) in local storage for later use. The pre-processed model is then used to train the summarization model through the Pointer-Generator model. When the model spits out a summary given an input, it looks for the saved file with the nouns and the pronouns and replaces all the repeated nouns with the pronouns in the file. Here is a chart that shows the model:
The coreference_resolution_pipeline branch adds a third pipeline where it contains a model that is trained purely on just the nouns that have pronouns in the input data (e.g. "Wayne saw himself." becomes [84123, 1512, 634] which gets processed and becomes [84123, 0, 0]). This pipeline of data is then taken into consideration at the final step of the Pointer-Generator model which is the switch that determines whether to obtain the word that is to be outputted from the vocabulary pool or the input document. Judging from the word that is to be outputted, there is a check that sees if that word is a pronoun. If it is a pronoun, the third pipeline kicks and and is used to output a word that it thinks it is correct. Because this pipeline of data has heavily emphasized weights on the nouns that have pronouns, there is a high chance of producing the noun that the pronoun is referring to instead of passing the pronoun through. This model aims to mainly solve the problem of pronouns being used without being defined first which creates the most confusion in a generated summary compared to other pronoun issues. Here is a diagram of the model:

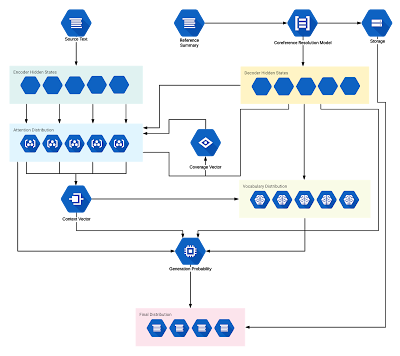
Just as a reference, here's the baseline model (Pointer-Generator model):

The results are surprising.

Although the improvements are slight, most models show improvements over the baseline model. Here are the explanations of each category:
The two_models branch utilizes two models: an off-the-shelf Coreference Resolution model and the Pointer-Generator model. The Coreference Resolution model is used during pre-processing and post-processing of the data. Before the training data is fed into the Pointer-Generator model to train the automatic summarization model, the data goes through the Coreference Resolution model where the model replaces all the pronouns with the noun that the pronouns are referring to (e.g. The text "Wayne saw himself." becomes "Wayne saw Wayne.") and saves the noun and the pronouns (e.g. {Wayne: [he, his, him, student]}) in local storage for later use. The pre-processed model is then used to train the summarization model through the Pointer-Generator model. When the model spits out a summary given an input, it looks for the saved file with the nouns and the pronouns and replaces all the repeated nouns with the pronouns in the file. Here is a chart that shows the model:

The coreference_resolution_pipeline branch adds a third pipeline where it contains a model that is trained purely on just the nouns that have pronouns in the input data (e.g. "Wayne saw himself." becomes [84123, 1512, 634] which gets processed and becomes [84123, 0, 0]). This pipeline of data is then taken into consideration at the final step of the Pointer-Generator model which is the switch that determines whether to obtain the word that is to be outputted from the vocabulary pool or the input document. Judging from the word that is to be outputted, there is a check that sees if that word is a pronoun. If it is a pronoun, the third pipeline kicks and and is used to output a word that it thinks it is correct. Because this pipeline of data has heavily emphasized weights on the nouns that have pronouns, there is a high chance of producing the noun that the pronoun is referring to instead of passing the pronoun through. This model aims to mainly solve the problem of pronouns being used without being defined first which creates the most confusion in a generated summary compared to other pronoun issues. Here is a diagram of the model:

Just as a reference, here's the baseline model (Pointer-Generator model):

The results are surprising.

Although the improvements are slight, most models show improvements over the baseline model. Here are the explanations of each category:
- ROUGE
- Recall-Oriented Understudy for Gisting Evaluation
- Measures not the fluency of the generated summaries but rather the adequacy of the generated summaries compared to the reference summaries
- ROUGE-1
- Measures the overlap of unigrams (one word at a time) between the system summaries and the reference summaries
- ROUGE-2
- Measures the overlap of bigrams (two words at a time) between the system summaries and the reference summaries
- ROUGE-L
- Measures the longest matching sequence of words using Longest Common Subsequence (LCS) based statistics
- LCS
- Unlike comparing substrings, LCS is more lenient and true to the purpose of summarization in a way that the subsequences are not required to occupy consecutive positions within the original sequences
- Recall
- Measures how much of the reference summaries the generated summaries are recovering/capturing
- Precision
- Measures how much of the generated summaries are in fact relevant/needed
- F-Score
- Considers both Recall and Precision scores and produces a harmonic average between the two
As you can see, the baseline did better in all of the Precision categories which means that the summaries generated by the baseline model contains a lot of information that is in the reference summaries. This is an important category as it determines whether the generated summaries are producing relevant information. However, the two created models excels in all of the other categories with the coreference_resolution_pipeline model being the best with an improvement of 0.0047, 0.0022, and 0.0006 on ROUGE_1_F_SCORE, ROUGE_2_F_SCORE, and ROUGE_L_F_SCORE respectively. These scores can be interpreted as the coreference_resolution_pipeline model produced a more adequate summary by 0.47% in terms of unigrams, 0.22% in terms of bigrams, and 0.06% in terms of LCS.
Although these improvements can be seen as very small, the most surprising fact is that the baseline model was trained for about 4 days while two_models was trained for 2 days and coreference_resolution_pipeline was trained for only 1 day. For each step/iteration of training (i.e. for each training data), the baseline model took on average 0.5 seconds on my GTX 1080, two_models took 0.7 seconds, and coreference_resolution_pipeline took 0.9 seconds. So combining these two sets of facts, the two new models was trained significantly less especially the coreference_resolution_pipeline model but still did better than the baseline model.

Comments
Post a Comment