Final Post

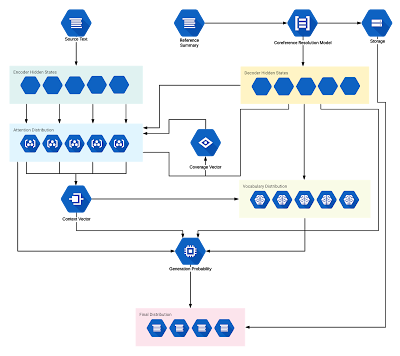
Introduction This project aims to explore the research done on automatic abstract text summarization and look for ways to improve the model. The topic of automatic text summarization was chosen because of my interest in cutting down time spent on reading materials that could be dry and dull on occasions. With the rise of popularity in Neural Networks and my previous knowledge in Machine Learning, I wanted to study and learn more about the development of automatic text summarization tools. While there are two fields of automatic text summarization (extractive and abstractive), I focus on abstractive approaches due to its higher difficulty and significance in creating a human-like summarization tool. Here is a general overview: Existing Work Automatic text summarization is considered a sequence-to-sequence problem (seq2seq); meaning, it's a prediction problem that takes a sequence as input and requires a sequence as output. For seq2seq problems, Recurrent Neural Networks...